Evolution of Application Workloads

The first blog of this three-part series discussed the need to have a trusted partner to guide you along your containerisation journey – someone who has been there and done it before – to help you avoid the pitfalls and work in partnership to help select the right kit to facilitate your successful journey. In this second instalment, we’ll explore the evolution of application workloads over the last couple of decades and discuss how the operational mindset and management tooling needs to change within the organisation to facilitate a successful digital transformation journey.
In the early days of IT, every workload in existence ran on what is termed “bare metal” – basically one physical server per application. Back then there was no separation between the physical machine and the application workload it was running. There were no hypervisors to provide an abstraction layer between the application components, well not on x86 workloads at least!
.The application, its supporting libraries and operating system (OS) all ran directly on the physical hardware that “the workload” was installed on. This approach was extremely inefficient – although the majority of physical servers only ran at 20-30% utilisation for most of the time, you also had no choice but to design the platform for maximum peak utilisation, otherwise, users would experience performance issues with significant peaks and troughs in application demand.
Then, along came VMware in the late 90s, launching their GSX (hosted) and ESX (hostless) hypervisors in 2001. This was a real game-changer within the IT Industry, now you could “virtualise” the application workload within a virtual machine (VM) – and if you were clever, you hosted workloads with different performance schedules on the same physical kit to drive up overall hardware utilisation on the physical host.
In its simplest concept, the ideal for VM workloads was to host an application that was heavily utilised during the day, with another workload that was heavily utilised during the night. By hosting both workloads on the same hardware, each in their own VM, both workloads could access the resources they needed from a single host, driving up utilisation of the underlying, compute, network and storage sub-systems.
From 2001 to 2010, VMware remained dominant in the hypervisor market and it wasn’t really until Microsoft launched Hyper-V 2012 R2 that they had serious competition. I remember deploying VMs for the first time with ESX 1.2 across a full-service provider’s infrastructure. The technology was fairly new but it delivered results immediately and we saw utilisation of RAM and CPU go from around 20-30% up to 60-80% in the new “virtualised” environment.
As hypervisors matured, features like vMotion, which automatically monitored VMs and moved them between physical hosts in the event of hardware failure, application uptime improved. If an individual VM host failed, vMotion simply moved the VM to another available host.
The tech-world does not stand still when it comes to performance, automation and scale.
So, in 2013 a small tech start-up based in San Francisco called Docker began work on a set of Platform as a Service (PaaS) products that used OS-level virtualisation to deliver software in packages called ‘containers’. The concept had actually been around since BSD jails and Solaris zones in the early 2000s, but it was Docker that brought them to x86 and provided the initial tools required to deploy them at scale.
Containers, like VMs, are isolated from one another and bundle their own software, libraries and configuration files into a single package that can access platform-level resources (Kernel runtime, RAM, network, storage). However, unlike VMs, containers do not require a full host OS to be built into them because the Kernel and platform resources are shared with the container at runtime from the host via the Container Engine.
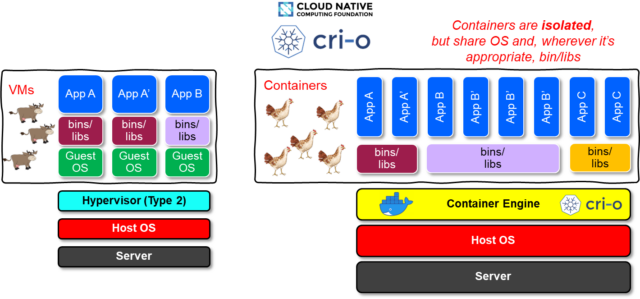
The above diagram illustrates the core differences between VMs and Containers at the host level.
Because the container does not require its own version of the host OS to be embedded within it, containers have better performance characteristics than VMs. This equates to greater density on the host hardware.
With container density often as high as 10:1 containers per host in pre-production environments, and on average 4-6:1 containers per host in production environments, the potential for reducing hosting costs per application workload instance is one of the major attractions of containerisation.
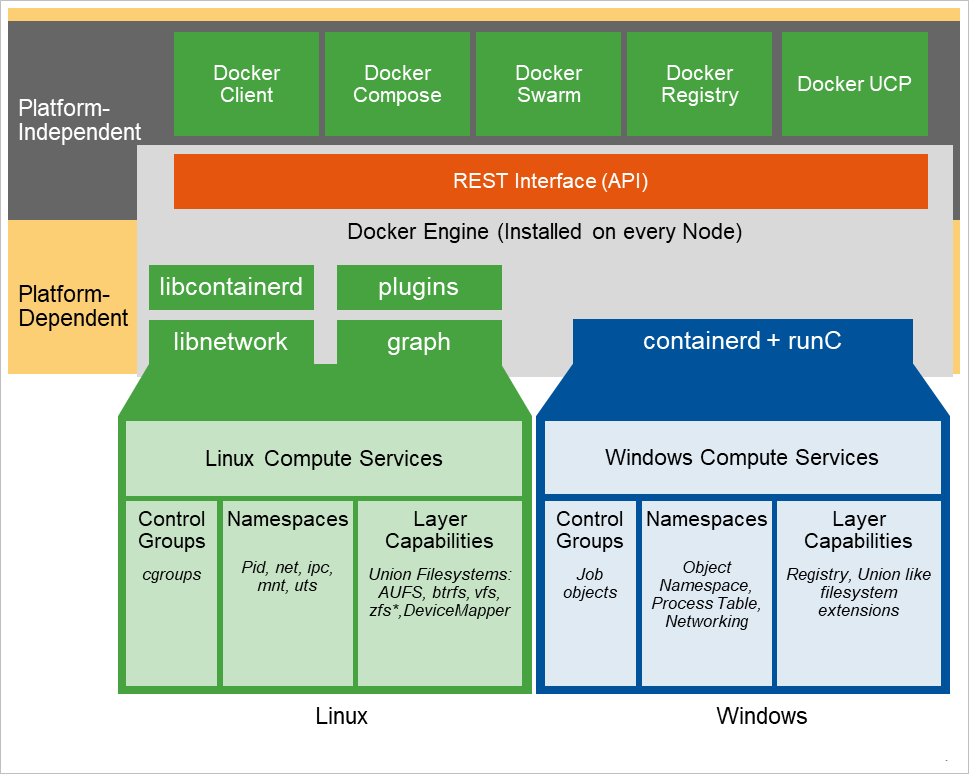
Please remember though, a Linux container can only run on a Linux host and a Windows Container can only run on a Windows host, the control plane is platform-independent but the container itself is platform-dependant and can only run on a Kernel of the same type, as shown in the diagram below:
Couple this density with automated horizontal scale-out capabilities facilitated by microservices architectures, with the self-healing orchestration capabilities of Kubernetes, and you have a very efficient, powerful hosting solution for those mission-critical application workloads.
Now let’s explain Containers in terms of Pets, Cattle and Chickens…
There is a popular description of containers that uses the idea of use in terms of pets, cattle and chickens: “Bare Metal Servers are like Pets”, “Virtual Machines are like Cattle” and “Containers are like Chickens”. Let’s look at the distinction.
Pets are not heavily stressed by ‘utilisation’ in their daily life, just like bare metal servers! They also take a fair bit of looking after. If they get ill, we nurse them back to health while continually worrying about them until they are better. With all this effort required, it limits the number of pets you can realistically manage at any one time.
When a business needs to step up in scale, it’s time to start virtualising workloads and divorcing them from the underlying hardware layer via a hypervisor. This management style can be thought of in terms of farming cattle.
By managing virtualised workloads like cattle, we can scale and industrialise operations from cradle to grave throughout the lifespan of our livestock.
When needed, we auto-deploy to provision, thus minimising the opportunity for manual error and maintaining a high-security posture by reusing templates that are constantly being refined. This breeding program ensures we get the best livestock (VMs) we possibly can at each cycle.
During the configuration phase, we monitor closely, test, and retest to ensure we have a healthy product and then we maintain it, applying patches, and monitor it to keep the workload healthy.
Finally, the VM will reach end of life and be decommissioned safely to dispose of the data. The whole process is industrial but still a time-consuming management methodology, and not necessarily very agile if we suddenly get a spike of very high demand.
Chickens on the other hand, in an intensive farming scenario, has a fully automated lifecycle that is much shorter than that of cattle. Chickens have a much shorter gestation period than cows, which means it is more of an “on-demand” resource – “if we want more eggs, we spin up more chickens”.
When a container’s lifecycle is automated in Kubernetes, the application architecture that presents the application will usually be made up of multiple, small microservices each residing in its own container. These containers are used to define the application architecture in an object called a ‘pod’. Multiple pods can be hosted within Kubernetes and each pod defines an individual application’s architecture.
When application architecture components are microservices-based, high availability and performance scale-out capabilities can be easily achieved.
In these scenarios, real-time performance metrics are fed into the container orchestration layer (e.g. Kubernetes or Docker Swarm) which allows the application to be scaled at the individual microservices tier by simply adding more containers (scale-out). This increases the capacity at the microservice tier automatically as soon as the monitoring tool identifies performance degradation.
Once the performance is back within acceptable service limits, the orchestration layer begins scaling back by terminating the additional containers deployed during the scale-out.
This dynamic management of resources and elasticity of these types of solutions have the greatest return on investment (ROI) in the cloud and are exactly how companies like Netflix, eBay and Google scale or shrink their environments to optimise hosting costs whilst maintaining performance at peak times of service.
Video: Container Management in a Production Environment
Below is the second of three videos that were recorded during a client webinar hosted by CSI and IBM.
In this section of the video, Randy Arseneau from IBM shares both the basic and more complex aspects of Container Management in a Production Environment.
For the third blog in the series, please click here: Not just Workload Modernisation, Explore Full Stack Automation
***
If you wish to get in touch to discuss anything raised in this blog, please use our Contact Us Page.
Ready to talk?
Get in touch today to discuss your IT challenges and goals. No matter what’s happening in your IT environment right now, discover how our experts can help your business discover its competitive edge.